Tornado跳坑记

我司有一个内部HTTP服务,提供实时的到车时间数据。虽说是内部服务,但其实我司App的请求很大一部分都经过App后台从这里获取数据,因此QPS的要求不算低,至少对活跃用户数敏感。自从去年大概10月份我接手这个服务以后,一直进行bug修复和功能上的迭代,不温不火,风平浪静。
直到去年12月4号傍晚,该服务在某个城市的部署开始出现响应时间显著增大的故障。当时分析了一下log,发现请求数是从某个分钟开始激增,几乎在一两分钟内就增大到之前的2倍,然后俺的服务就扛不住了(哭,不好意思说只是从50涨到100左右。。),响应时间开始变成数秒到十几秒不等,反应在App上已经是啥都刷不出了。不过持续一个小时之后又几乎是瞬间恢复到正常值。当时我觉得如果是晚高峰用户激增,也不至于这么直上直下的,一定是竞品在爬我们,嗯,即使用户逐渐增加,也不会很快double吧,然后就没放在心上。
不料,后来陆续有其他城市出现相同的问题,而且也是在相同的晚高峰时段。这时同事指出请求激增可能是雪崩效应——咱App不是推送的模式,要用户手动刷,用户刷一次没有响应,自然就继续刷,请求数就是突然飙起来的。结合逐渐增长的日活来看,这个很可能就是原因。然后才迟钝地意识到这是个严重的性能问题,而且100QPS就扛不住了也是说不过去。不得不开始认真审视这个服务。
开工
这个服务基于Tornado,出于不知道的什么原因,没有用Python 3,而是Python 2.7.9。但是对于我一个刚刚接触Python几个月的菜鸟来说,并没有什么区别。Tornado是Python社区里优秀的web服务框架,据说在开发高并发服务的领域非常出众。我tm原来都是写Java的,虽说也写过很有几个人用过的web应用,但是估计QPS能有几十就不错了。正面肛QPS和响应延时对我来说其实相当新鲜。OK那就开始看看Tornado到底哪里牛逼了,然后我司的这个服务到底是怎么用它的。
ab
为了复现高请求数的场景,经同事介绍,接触到了入门级压测工具ab(ApacheBench)。ab的基本使用很简单,一个可用的最简命令如下(使用50并发发送100个请求测试我司主页):
ab -n100 -c50 'http://www.chelaile.net.cn/'
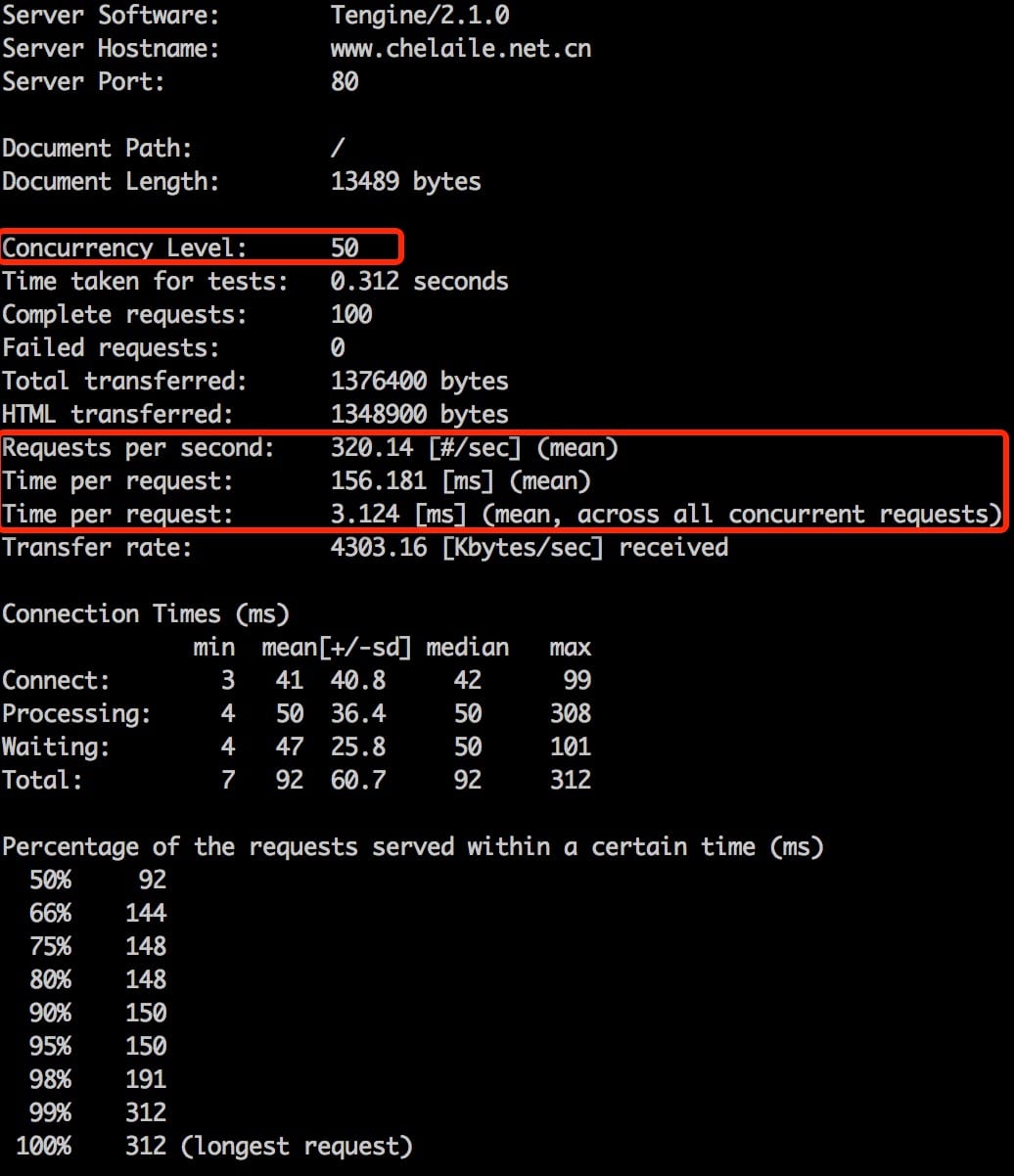
以上是样例测试结果,简单介绍下几个重要的指标:
- Concurrency Level 即命令中-c提供的参数,表示ab在用多少个并发的通道不断发送请求,每个通道都是接受到上个请求的返回即立刻发送下个请求。各个通道间互不影响。可以理解为ab使用的-c车道的公路进行测试。
- Requests per second 即是服务表现出的QPS
- tpr1 = Time per request (mean) 是所有请求的响应时间的平均值
- tpr2 = Time per request (mean, across all) 是tpr1/Concurrency Level,相当于看成如果每个请求依次处理,每个消耗的时间。由于处理每个请求的时候可能有待其他资源,而"等待"不是互斥资源,是可以大家一起等的(当然,这得以多线程或者非阻塞IO为前提),所以平摊下来tpr2会(远)小于tpr1。
稍微分析下这些指标的关系和规律:
- 并发数和QPS有何关系?一般而言,服务能提供的最大QPS会在在一个并发数BEST_CONC 附近达到。实际并发数少于BEST_CONC 时,没有榨干服务的性能;并发数过大的话,服务不能及时处理的的请求会被排队,排队也需要耗费部分资源,所以QPS会略有下降。
- QPS和tpr2互为倒数。当并发数使得服务的性能达到最值时,稳定下来的是这两个值。
- tpr1里其实包含了来不及处理导致的排队的时间。可以发现,当Concurrency Level接近于QPS极限的时候,tpr1约为1秒左右。
- 为了提高性能,本质上要减少tpr2。这可以从不同方面着手。
IOLoop及其他
Tornado的高并发能力很大程度基于其IOLoop这个类。这是一个单线程非阻塞的模型,我没看过源码,但是看介绍和Node有些类似。写个QPS令人满意的Hello World也许很多框架都能做到,而Tornado强大之处在于处理请求过程中,如果依赖其他资源,能很好地协调。但这需要开发者把各种外部资源的请求以非阻塞的风格实现。
Tornado有个很方便的装饰器@gen.coroutine,依赖Python的生成器,实现了一套await async的语意,来实现非阻塞的功能,以避免书写出各种callback hell。(当年写Node是不是因为这个很痛苦?(我说错了别打我)另外,好像最近慢慢有各种语言都开始在语法层面支持await和async。甚至在Python3上使用Tornado已经用这对关键取代了@gen.coroutine,都是后话)
跑完题回来,鄙服务依赖的资源有:
- 其他内部HTTP服务
- Redis
- OCS (嗯。。aliyun用户)
- sleep (耗费时间的都是资源,嗯)
当年写Virtual Judge时候完全靠 线程池+各种阻塞操作 撑起来的那点并发在这里完全用不上啦。在单线程里一定要慎用阻塞操作,除非对响应时间非常有信心。对于上述资源里我们分别使用的是:
- Tornado自带的Asynchronous HTTP client。最开始我还觉得一个Web服务还自带HTTP client,真稀奇。
- redis-py。这里使用的是阻塞操作,不过我们对Redis的操作不多,而且它的响应时间确实可以称得上让人放心。刚看了下redis-py好像支持非阻塞操作,但是我们最近已经逐渐移除了对Redis的依赖,不管了。
- bmemcached。这货是阿里云官方推荐的OCS的Python客户端,后面和他的故事还多,这里按住不表。
- gen.sleep()
看上去挺祥和,其实不然,我不太想再回忆一遍跳坑的过程。
凭空多出的响应时间
同事推荐使用听云来监测服务中的瓶颈,但是我配了半天也不上传数据,无法在听云那边看到监测结果。所以就决定用time.time()来手动查看每段可疑代码的运行耗时了。(后来才知道也可以用cProfile,用起来也很简单:python -m cProfile -o /tmp/prof start-script.py, 再python -m pstats /tmp/prof)
(此处略去一万字在代码中打点计时的操作、以及几十次rsync后的心得)
最后确实发现了不少零零碎碎的地方可以加速。但是修补之后还是发现响应时间不对劲。上代码,简化一下大概是这个样子:
@gen.coroutine
def process(key):
temp1 = yield func(key)
temp2 = yield ...
result = yield ...
raise Return(result)
class SingleHandler(web.RequestHandler):
@gen.coroutine
def get(self):
key = self.get_argument('key')
result = yield process(key) # hehe
self.write(result)
class BatchHandler(web.RequestHandler):
@gen.coroutine
def get(self):
keys = self.get_argument('keys')
results = yield map(process, keys.split(',')) # hehe
self.write(','.join(results.values()))
大概逻辑就是服务提供两个endpoint,一个是查询一个key,一个是查询多个key,两种查询的逻辑其实完全相同,于是就拎出来作为公共函数process()了。但是从ab测出的结果来看,不论单个查询还是批量查询,时间都比标有# hehe的行耗时要大。
想了许久才弄清楚原因:在@gen.coroutine装饰过的函数里,每yield一个Future,Tornado其实是在IOLoop里注册了一个callback。问题就出在单线程的IOLoop就那么一个,callback也是要排队的。所以有这样一种可能,在hehe开始之前,注册了callback,然而这个callback此时已然排在队列的非常靠后的位置,以至于当hehe那行都yield结束,只差写response的时候,还没轮到该callback执行。凭空多出的响应时间就在这里了。
从结果上看看这个问题:也就是相当于处理每个请求都白白多sleep了若干时间,好在由于这个时间不是独占的,对最大QPS其实不会造成太大影响,只是为了达到到相同的QPS,需要更大的并发才行,而且上述的tpr1全都变大不少,这确实是降低了性能。
至于解决办法:本质上我其实希望在IOLoop上的这些Futrue的callback是有优先级的,但搜索了半天并没有查到相关内容,这令人困惑。我能想到的办法有两种,一是再开一个线程用另外一个IOLoop来安排优先级较高的callback,这太麻烦了,而且Tornado各种线程不安全;二是使用最原始的把callback作为参数传递的办法来控制callback的执行顺序(据说CPS是最灵活的,这不得不承认)。
然后我就用方案二了。所以最后我混用了@web.asynchronous和@gen.coroutine。虽然到处都在说@web.asynchronous已经过时了,应该使用@gen.coroutine,但是我确实没有找到更好的办法,而且这种方案也证实效果不错。
战OCS
我们一开始使用本地Redis作为缓存,但是本地缓存不容易水平扩展,而且占用一部分机器内存。阿里云的OCS其实是个云memcached,现在已经改了名叫“云数据库Memcache版”,价格比“云数据库Redis版”便宜,我们就逐渐从Redis往OSC迁移了。
标准memcached不带验证功能,memcached官方也是建议使用内网访问加无认证的方式使用。而OCS则使用了SASL扩展来给memcached做认证功能。bmemcached是Python社区里唯一一个实现了SASL扩展协议的库,于是成为了阿里云推荐的OCS的Python客户端。
背景就是这么回事。这玩意开始用得也没啥问题,但是到了后来我排查性能发现读OCS占用了处理请求超过一半的时间,只好正面肛一下。我们在OCS的数据有两种,一种是不怎么会变的,一种是有其他内部服务在频繁更新的。对于前者,我把热数据在内存里用LRUCache缓一缓。由于后者的存在,仍需要严肃地优化读取。之后就走上了一条惨痛的路。
最先暴露出的问题是bmemcached是阻塞的,而且也没有提供非阻塞的读写接口!我们这里读OCS的频率挺高的,总是阻塞显然不可行。于是屁颠屁颠去Github上找非阻塞memchached客户端,找了一圈确实找到了几个,甚至还有专门为Tornado定制的版本,比如asyncmc。但是很快就发现他们都不支持SASL扩展。开始有点不甘心,要不自己改改看?我觉得吧,相比把bememcache改成非阻塞的,给asyncmc加个SASL协议应该容易不少吧,毕竟协议网上都查得到。一查,伤心。memcached支持2种协议,PLAIN_TEXT的和BINARY的,而SASL只能在后者上面实现。那些没实现SALS的库则无一例外都是基于PLAIN_TEXT协议的。我开始觉得不能再浪费时间了,得快点整个切实可用的方案出来。然后脑洞就开歪了。。
我当时寻思Python的客户端没有非阻塞的,但是Java的客户端有啊,给包装一下,适配成一个HTTP形式的客户端就好了,毕竟我大Tornado的async HTTPClient强大着呢。虽然这么倒来倒去估计会增加一些额外的耗时,但是非阻塞多牛逼啊应该能掩盖掉这一部分不足吧。于是就开始计划用Spymemcached和Netty整一个出来。没多久又手贱搜出shade来,跑在Play frameworkd上面,性能肯定杠杠的,要写的代码也很少,于是很快就搞起来一个。谁知拿到服务器上一跑当真是惨不忍睹,比bmemcached还慢了不少。回过头来仔细想一下,一秒钟往一个内部HTTP服务上发100个请求,可都是短连接啊,蠢爆了。
其实最开始我是知道memcached有批量读的接口(get_multi)的,然而因为有一批较早的数据因为写入时key编码的问题(用bmemcached写的时候key千万别用unicode,用str,否则会有各种问题)导致get_multi抛异常。把上面那个被称作memcached-proxy的东西废掉一段时间后,我又开始重新打get_multi的主意。终于反应过来,如果get_multi出了问题,就一个一个先按unicode单条读出来,再把key转成str写回OCS去,之后就可以批量读了。之后实测了一下get_multi的性能,发现相比与一条条串行地查询,当查询的key超过20,提速就可以稳定在七八倍的样子了,这是相当可观的优化。另外,如果一次装箱的请求包含重复的key,相当于进一步提速了。
可以批量读之后,就是决定怎么装箱请求,什么时候发送读请求的问题了。我的一个粗糙的思路是:一次实际的get_multi好比一次班车,一次班车最多等待T ms,将搭载过去T ms到达的请求一次性发给OCS。原来写Java也做过类似的功能,记得当时用了一个阻塞队列搞得相当麻烦。这次在Tornado尝试里写了一下,意外发现非常简洁,献丑贴一下:
class MemcachedClient:
def __init__(self, mc_address, mc_username=None, mc_password=None):
self.mc_address = mc_address
self.mc_username = mc_username
self.mc_password = mc_password
self.plain_mc_client = bmemcached.Client([mc_address], mc_username, mc_password)
self._batch_keys = set()
self._batch_values = {}
self._get_async_batch_future = None
self.wait_time = 0.05 # in seconds
@gen.coroutine
def _get_async_batch(self):
"""
Fire a batch of requests that arrived in last {self.wait_time} seconds
"""
yield gen.sleep(self.wait_time)
values = self.plain_mc_client.get_multi(list(self._batch_keys))
self._batch_keys.clear()
raise Return(values)
@gen.coroutine
def get_async(self, key):
"""
Query by joining & waiting for next batch
:param key: query key
"""
self._batch_keys.add(key)
if not self._get_async_batch_future or self._get_async_batch_future.done():
self._get_async_batch_future = self._get_async_batch()
batch_values = yield self._get_async_batch_future
raise Return(batch_values.get(key.decode(), None))
get_async()即是对外的接口。这里强制将等待时间一律设置成为50ms,也许你一眼就看出,这回使得在请求数很低的时候,处理时间也至少会在25ms左右,这或许并不划算。这的确是是个问题,不过考虑到内部服务来调用我的时候还有其他round-trip的开销,和那些开销加起来之后,我这里的的处理时间是不是大头还要打个问号,所以就偷个懒到此为止了。但是没错这里确实是可以再优化的。需要注意的是,这个版本是为了批量查询专门优化的,对串行的查询并不友好。
日志
最初的版本就用了Tornado的多进程来提升一些性能,然而Python的多进程没法同时写一个日志文件,于是日志打得乱七八糟,还有遗漏。有了新的的机器之后开始把服务镜像部署到多个机器上,用nginx来负载均衡。这时log写在不同机器上,查看非常不方便,于是终于到了把log打到一处的时候。很自然的方案是用logging的SocketHandler,然而我发现这个东西非常慢。用了它之后几台机器能达到的总QPS居然和一台机器差不多,我只能理解为SocketHandler确实很慢。(@,@)
好在从Python3开始logging提供了QueueHandler来通过多线程分担出logging的任务,Python2则可以使用logutils这个lib来扩展获得这个功能。用了这个方案之后,终于看到QPS达到可以接受的水平。
收工
代表性略小一点的坑和填补过程就不再罗列了,免得使这篇已经够啰嗦的流水账更加不堪入目。这两周多的跳坑过程令人烦心之处在于,在看到满意结果之前,一直都怀疑是不是以我的能力最后也不能优化成功,是不是之前花费的时间都白费了。在这种功利和现实的条件下,也只有令人满意的结果具有实际意义。另外感受深刻的一点也是之前常听说的一句话:一行看上去稀疏平常的代码,如果没有参与过,你无法想象它是踩过多少坑,推翻过多少历史版本才得到的。