Kaggle 101 Digit Recognizer试水
断断续续花了好久看完了《统计学习方法》之后,虽然里面的推导绝大部分都曾经看懂过,然而却发现自己并没有入门,里面的原理要我自己手推未必能推出,而且也不能清晰地分辨出里面各种方法的从动机到适用范围的区别。反而,耳濡目染,越来越多地听说一些书中从未涉及的内容,水深令人难以想象。理论虽然重要,实践更不可缺少。所以先到著名的Kaggle上尝试一下。
Kaggle上有几道长期有效的101入门题目。有一道预测泰坦尼克号乘客获救情况的题目,里面有很多详细的工具类教程很有帮助,不过该题题意不是和算命很像,而完全就是算命,非常玄乎,知难而弃。
于是尝试另一道数字识别的题目。题意是给你42000个28x28像素图片,每张上面有一个手写的[0-9]字符,并告诉了每张上面实际的数字,作为训练集;另给28000张同样风格的图片作为测试集,求这些图片上的实际数字。识别的正确率就是队伍的分数。目前有1270个队伍参加了这次“比赛”,有1165个队伍的识别率在90%以上,非常厉害。
这题看上去似乎是一个分类的问题。《统计学习方法》里介绍了很多分类方法,考虑到逻辑回归(Logistic Regression, LR))思想简单,实现方便,我打算使用它来解决此题。Kaggle有个好地方,里面有很多乐于炫技的老鸟分享高质量的代码供学习,很适合我这种初学者。而且第一页就发现有个用LR的。
逻辑回归(LR)
简单介绍一下LR。LR本身是个解决二分类问题的方法。LR假设数据集按照分类基本是线性可分的,在此基础上尝试找到一条向量,使得不同类别的数据集在这条向量上的投影交集尽量小。从大了讲,从感知机到LR到SVM干的都是这么一件事,而LR的特点是对于给定的分类模型(就是那条向量),可以对数据集的每个点给出它属于每个分类的概率。LR的直接输出是连续值概率,而非类别,所以一般称作“逻辑回归”而非“逻辑分类”。
对于给定的模型Θ,每个点属于哪个分类由以下公式定义:
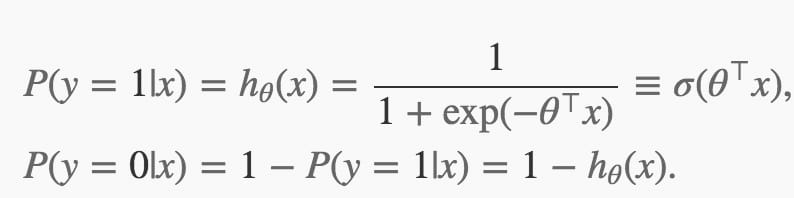
模型Θ的损失函数J(Θ)由以下公式给出:

我没弄明白J(Θ)为啥要定义成这样,是不是因为这样▽J(Θ)形式比较简单?:
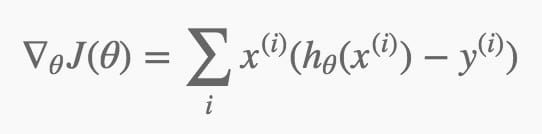
有了这几个式子就可以使用梯度下降的方法迭代出一个靠谱的Θ了。
用LR解决多元分类问题
原始的LR解决的是非黑即白的二分类问题。诸如这道Kaggle的一类问题,类别数量大于二,怎么搞呢?目前知道有两种方法。
- one-vs.-rest(或one-vs.-all,OvA或OvR)
每一个类建立一个唯一的分类器,属于此类的所有样例均为正例,其余的全部为负例。
每个分类器都给出所属的概率,对于每个数据点,选出它在各个分类器中被归为正例概率最大的分类。
- Softmax Regression
与其说是LR的扩展,不如说LR是Softmax Regression的特例。如果有K各类别,它的模型是K个向量。他将同时给出一个数据点属于每个分类的概率,且概率之和为1。具体内容参见上述链接。
实践
上面提到的现成的代码使用的是上节提到的OvA方法。代码大量使用numpy的矩阵操作,相当简洁。我稍微改了下提交,得到了0.91143的正确率。
不过,如OvA的Wiki里所说,他独立地考虑每个分类器,直接比较各个分类器的概率,结果受数据分布均衡影响,我考虑实现一遍Softmax regression。
自己一写才发现,实现上不是那么容易。Python自己的性能很捉急,如果可能,要尽量使用numpy来实现对数据的批量操作,而不要手写循环之类。numpy的风格是把很多常见的的操作符都扩展为可以对矩阵操作,个人觉得当矩阵的维数多起来,很容易就绕晕了,而且Python的无类型声明这点加剧了绕晕。感觉这种风格的书写比起函数式更加紧凑。也许用多了熟悉了常见的模式会习惯吧。最后我把别人的LR改成Softmax Regression后发现丑了很多,性能也下降得厉害。
慢就慢,丑就丑吧,激动人心的在后面,准确率高才是王道。激动地跑了下交叉验证,过了好久显示正确率在88%左右,我了个大槽,估计是我实现有问题吧。
困兽之斗
了解过有组合弱分类器得到强分类器的思路。本来打算用AdaBoost试试看,不过scikit-learn那个doc没看明白,就放弃了。这种轮子总不能自己再写一遍吧,以后再研究吧。。
突然想到不是有随机森林么,不是可以投票么,这个实现起来简单,我就把训练集分成10组投票试试。考虑到每个Softmax regression分类器是输出分到各组的概率,投票我就直接把概率相加了。想想感觉还比较合理。跑完交叉验证以后tm又是88%。哭。我开始想为什么只听说随机森林,没听说随机逻辑回归了,可能是有道理的吧?
本地有了多个版本,我开始对比跑的结果,看看大家争议大的图片都长什么样。一看果然,连我小学一年级的字都不如。不过看了一些也有了点想法,很多图片写的歪歪扭扭我是没什么办法,不过你写在角落里就一点点大,我还是有办法的。然后就写了个trim的预处理,把周围的空白裁剪掉,中间有内容区域按照比例放大到28x28。我把这个策略放在OvA LR上面,本地交叉验证最好得到了94%的正确率,然后交上去只有92%+,比预期着实差了点。
总结
后来还想到些其他提升方法,比如先把图片按照集中的区域强行分类一下。然后考虑到我是在学习ML,不是ICPC like,这种trick做多了也没有本质的意义,就没有尝试了。
即使是94%也只能在Board里排到相当靠后的位置。要说哪里不对劲,应该是大方向有问题。上面所有的办法都是直接把每个像素当成一个特征,如果一个字符图像做字粗的平移,按上面的方法根本不能识别出两者的相似性。能到90%的准确率大概是拜训练集数量之大所赐。LR倒没有什么问题,如果能提取更有效的特征,相信能做到更好。值得一提的是我曾经交过一个别人的裸的随机森林,正确率达到了93%+。如果只考虑像素为特征,个人感觉还是挺悲观的。
突然想到,如果是本科时候,给我这道题,我大概会问“给我训练集干啥?有用么?能吃么?”233。
试水就到此为止。我记得有次我买了当时最好的四阶魔方,练了几天,然后测了平均,到WCA官网去看了下成绩能排到什么水平,结果大跌眼镜,估计是国内倒数10名左右,然后我看了下那些四速真的排在倒数10名的人三速是什么水平,发现他们大概是30多秒。这个和我刚才自我感觉良好地跑完交叉验证之后的感觉很像。